Academics & PhD students
Ask your AI about a 2023 interview and get the actual quote.
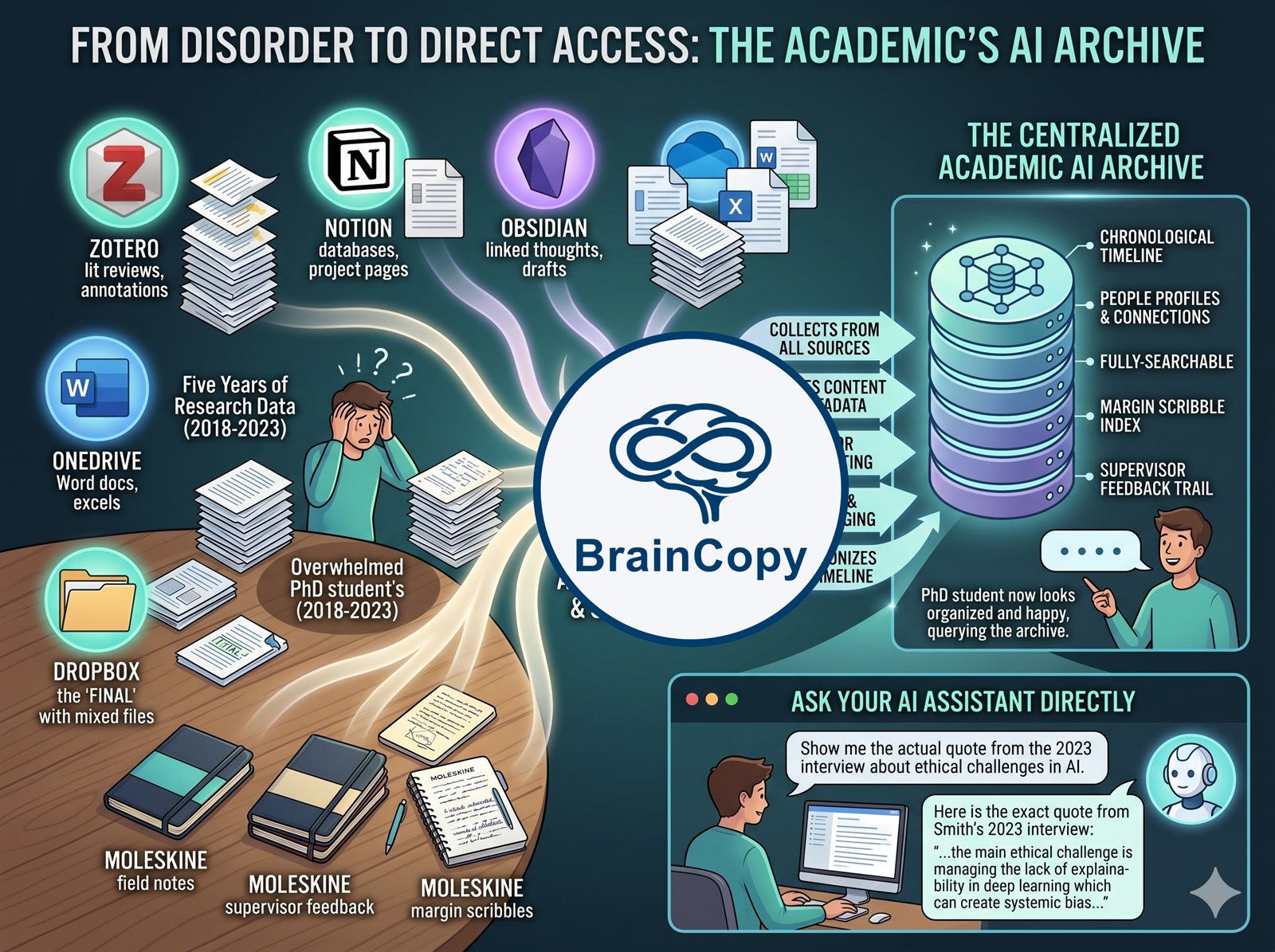
Five years of interview transcripts, field notes, lit review, supervisor feedback and margin scribbles — scattered across Zotero, Notion, Obsidian, OneDrive, a Dropbox folder called "FINAL" and three moleskines. BrainCopy pulls them into one chronological, people-aware, fully-searchable archive that your AI assistant can query directly.