AI power users
Your AI has no memory of you. Give it one.
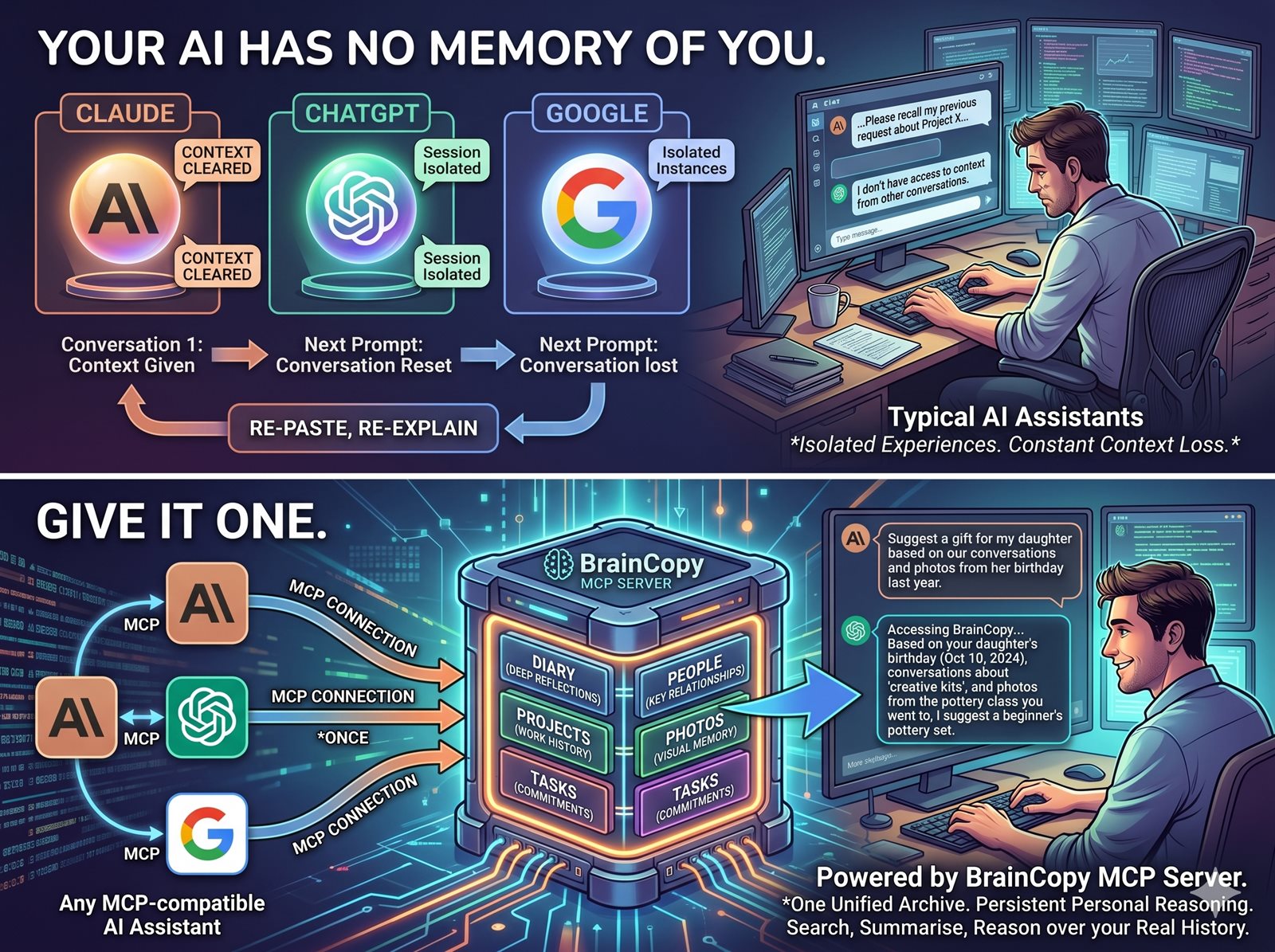
Claude, ChatGPT and every AI assistant you use resets every conversation. BrainCopy is an MCP server (Model Context Protocol — an open standard by Anthropic that lets AI assistants read data from external systems you control) backed by a structured archive of your actual life: diary, people, projects, photos, tasks. Connect once, and any MCP-compatible assistant can search, summarise and reason over your real history — not whatever you paste into the prompt that day.