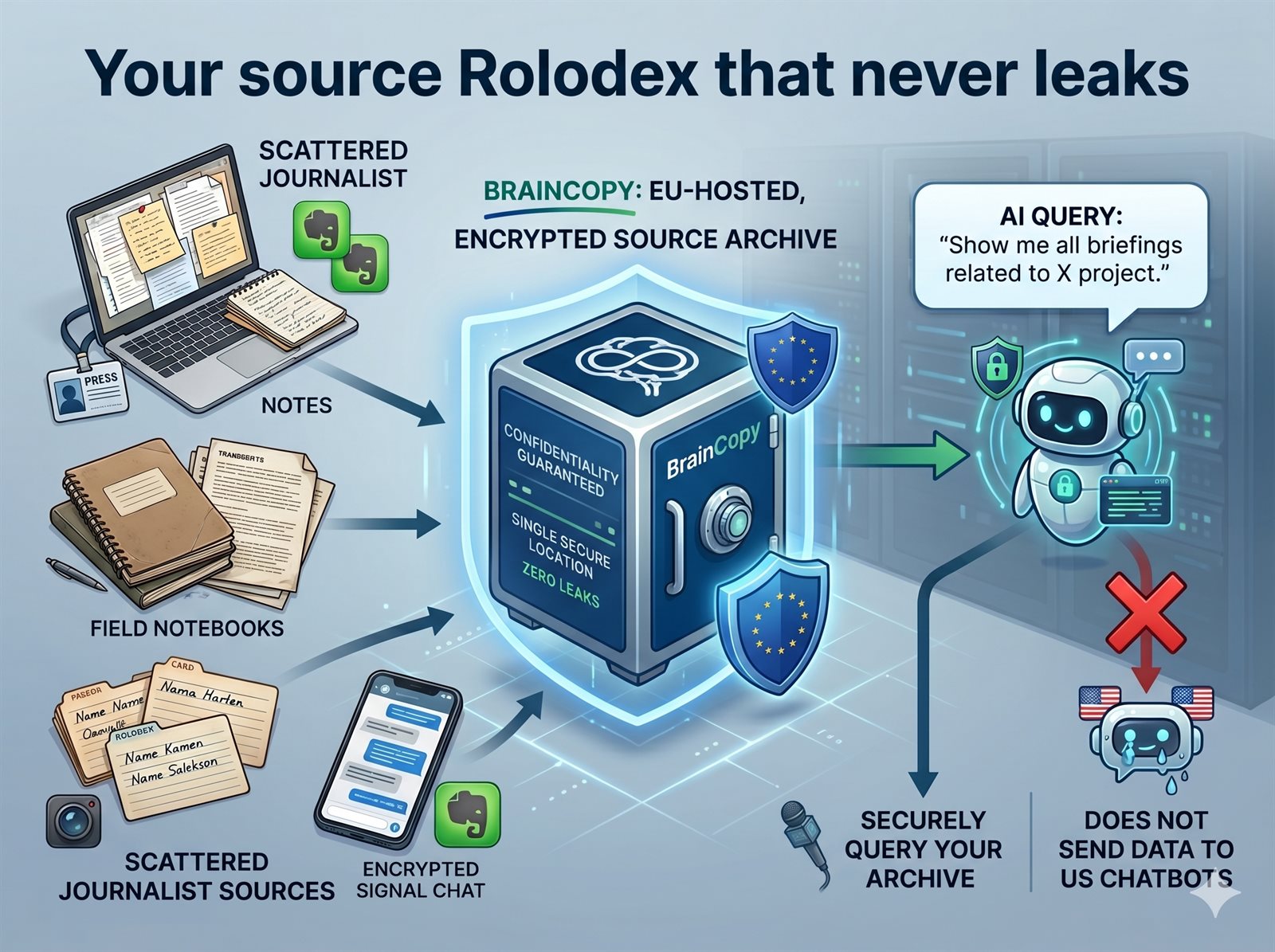
Five years into a beat you have a network of a thousand contacts, a hundred interview transcripts, and a dozen notebooks of margin reporting. Finding a specific quote from 2022 is a two-hour excavation, and you're not the only one who's taken notes — an editor, a producer, maybe a fact-checker each has fragments.
The modern note-taking stack — Notion, Evernote, Google Docs, iCloud Notes — is all on US infrastructure, none of it end-to-end encrypted against the platform itself, and increasingly entangled with AI training that your sources did not consent to. This is not just a GDPR issue; it's an operational security issue.
Your AI assistant would be transformative for reporting — "every source who mentioned X across my archive" — but you can't feed source material to a US chatbot without breaking trust and possibly breaking law, depending on jurisdiction.